StableDiffusion[0] = "Install"
![StableDiffusion[0] = "Install"](/content/images/size/w1200/2023/06/00000.jpg)
Les IA capables de générer des images ne sont pas si complexes à utiliser qu'il n'y parait.
Au contraire, utiliser ce type d'IA est plus simple que la photographie classique.
Vous devez toujours penser à ce qu'à quoi votre image doit ressembler (lumière, plan, sujets, angles, etc) mais vous avez l'avantage de pouvoir régénérer votre image à l'infini et modifier exactement ce qui ne vous plait pas dessus.
Stable Diffusion est un de ces modèles d'IA, contrairement à la majorité des modèles de génération d'images (Midjourney, DALL-E), ce dernier n'est pas vendu sous forme de service, mais est au contraire téléchargeable, utilisable et améliorable par tous. Grâce aux efforts de la communauté, de nombreux modèles spécialisés (pour générer des images d'animés, réalistes, avec des styles particuliers, etc) ont fait leur apparition.
Aussi, les ressources nécessaires à l'utilisation de ces modèles ont énormément diminué. Il est, par exemple, possible d'utiliser un Apple Mac M1 pour générer des images.
Si vous n'avez pas de carte graphique sous la main, vous pouvez utiliser des services en ligne pour déployer le logiciel utilisé.
Installation locale
Stable Diffusion est un modèle, pas une application. Pour l'utiliser (lui et d'autres modèles), une excellente application existe : Stable Diffusion Web UI par AUTOMATIC1111.
Cette application est simple à installer et à lancer, et permet de configurer tous les aspects des modèles utilisés.
Linux
Avec python 3, git et wget installé, il suffit de faire :
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)Et l'application sera installée dans le dossier "stable-diffusion-webui" de votre répertoire utilisateur. Pour la lancer, simplement exécuter le script "webui.sh" dans ce dossier.
MacOS
Avec brew (qu'il faut avoir installé au préalable) :
brew install cmake protobuf rust [email protected] git wget
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
cd stable-diffusion-webui
./webui.shDe même que pour Linux, il suffit d'exécuter le script "webui.sh" pour lancer l'application.
Windows
Installez python 3.16 et git
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webuiIl suffit ensuite de lancer "webui-user.bat" depuis l'explorateur.
Si votre carte graphique n'a pas beaucoup de VRAM (moins de 4G), vous pouvez lancer l'application avec le paramètre "--medvram" voir "--lowvram".
Pour cela, modifiez le fichier "webui-user.sh" (sur linux/mac) ou "webui-user.bat" (sur windows) et ajoutez "--medvram" ou "--lowvram" dans la variable "COMMANDLINE_ARGS" (et en décommettant la ligne évidemment si elle est commentée).
Medvram permet d'utiliser moins de VRAM, mais en contrepartie la génération sera plus lente.
Dans le cas où la quantité de VRAM serait très faible, lowvram permet de réduire au maximum la quantité de VRAM nécessaire. La génération sera extrêmement lente.
Modèles
Vous n'êtes pas encore prêts pour générer des images, il vous manque des modèles.
Les modèles sont les résultats d'entrainement, vous pouvez trouver des modèles spécialisés dans la génération d'animés, d'images réalistes, ou encore d'images X.
Les modèles Stable diffusion se placent dans le dossier "models/Stable-diffusion/" de l'application AUTOMATIC111.
Le modèle initial, stable diffusion 1.5, bon en tout, mais n'excellant en rien, est disponible ici (téléchargez-le ".safetensor")
Cela veut dire qu'ils sont capables d'en créer, et que certains modèles (notamment les deux que j'utilise dans la suite de cet article) sont très prompts à rajouter de la nudité dans les images générées.
Vous êtes prévenus !
J'utilise particulièrement deux modèles : Abyss Orange Mix V3 (Anime) et realisticVision V2.0 (réaliste) pour générer mes images.
Il est important de noter que le modèle Abyss Orange Mix V3 nécessite un VAE (un fichier supplémentaire à placer dans le dossier "models/VAE/") téléchargeable au même endroit.
Il existe énormément de modèles pour basiquement tout ce que vous voudriez créer.
Civitai est une plateforme de partage de modèles que vous pouvez utiliser pour trouver de nouveaux modèles.
Introduction
Il est maintenant temps de comprendre ce que vous pouvez faire avec. Comme lorsque vous apprenez à conduire, il va falloir comprendre quelle pédale agit sur quoi, et que font les boutons les plus importants.
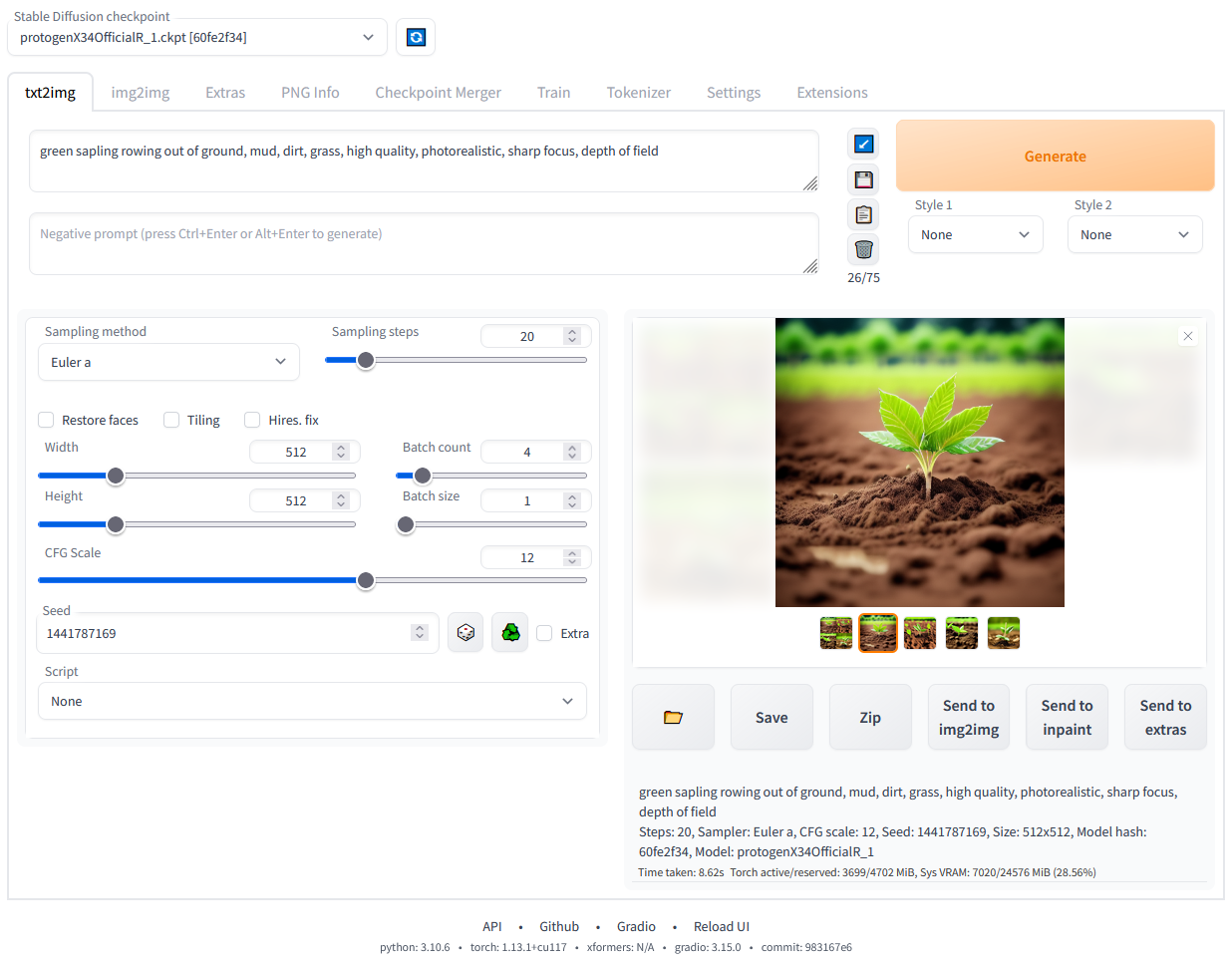
Txt2img
Permet de générer des images à partir de texte. C'est le mode le plus évident, et celui que vous risquez d'utiliser le plus souvent.
Vous commencez avec une "Prompt", une demande qui décrit votre image, par exemple "a woman, 21yo, sitting on a bench, in a park"
Le deuxième cadre juste en dessous contient là "negative prompt", l'IA ne comprenant pas correctement les négations, il n'est pas possible d'en mettre dans la Prompt. La negative prompt est donc là pour demander à ne pas rajouter des choses. Par exemple : "nsfw, nudity, nude, uggly"
La Sampling method est la manière dont votre image va être générée, la changer changera l'image que vous obtiendrez. Certains modèles vont vous en recommander une ou deux parfois. J'utilise généralement "DPM++ SDE Karras" ou "DPM++ 2M Karras"
La Sampling steps est le nombre d'étapes qui seront effectués, si le nombre est élevé, l'image prendra plus de temps, mais sera de meilleure qualité. Monter trop haut peut néanmoins causer des problèmes dans l'image.
La case Hires. fix permet d'augmenter la résolution de l'image (aux alentours de 512x512 pour l'originale). Lorsqu'elle est cochée, elle donne accès à plusieurs options, la seule que je change généralement est l'upscaler que je définis sur "Latent (nearest-exact)".
Width, Heigh permet de définir la taille originale de l'image. Une image trop grande ne sera pas générée par manque de VRAM.
CFG Scale règle la "force" de la prompt, un nombre bas et l'image sera éloignée de la demande, mais très créative, au contraire un nombre haut et l'image sera plus proche de la prompt, mais peu créative. De plus, un nombre trop haut, et des aberrations apparaitront sur l'image.
Seed, la graine de génération. La même graine, avec la même configuration et la même prompt génèrera la même image. La laisser aléatoire permet de générer des images différentes sur la même prompt. Si on la fixe, l'image sera relativement similaire à chaque fois (si la prompt ne change pas trop). Cela peut être très utile lorsque l'on arrive à une image que l'on aime bien, et que l'on veut modifier un détail : il suffit de fixer la Seed, et de modifier le détail dans la prompt, et l'image générée sera très proche de l'originale avec uniquement le détail voulu qui a été modifié.
Img2img
Parfois une image vaut mille mots
Génère une image à partir d'une autre image, on peut l'utiliser pour modifier des photos, ou souvent retoucher des défauts des images générées avec Txt2img. Il est possible de designer les zones de l'image à modifier, ce qui le rend très utile pour cette tâche.
On rajoute aussi une prompt et une négative prompt comme pur Txt2img pour indiquer au modèle ce qu'il doit faire.
Extra
Permet d'augmenter la résolution d'une image. Généralement, la dernière étape.
PNG Info
Permet de récupérer les informations d'une image (Prompt, Negative Prompt, configs, seed, etc). Très utile pour retravailler sur une image générée précédemment.
Let's go
Maintenant que vous avez les bases, il est temps d'essayer. Écrivez des prompts, comprenez comment le modèle répond à votre demande. Le prochain post portera sur comment générer des images d'animés avec STD.